Cache Notes
<p>Cache 可以说是计算机技术革命中最伟大的想法了</p>
想一个问题:在我们的电脑里,指令是怎么控制内存里的东西的?因为我们要运行电脑除了 CPU 以外我们要向外 拿取 数据才能执行一系列的指令,这样电脑才算运行起来。
让我们来看下面的这张图,这是十分完整的计算机组成结构:
Components of a Computer
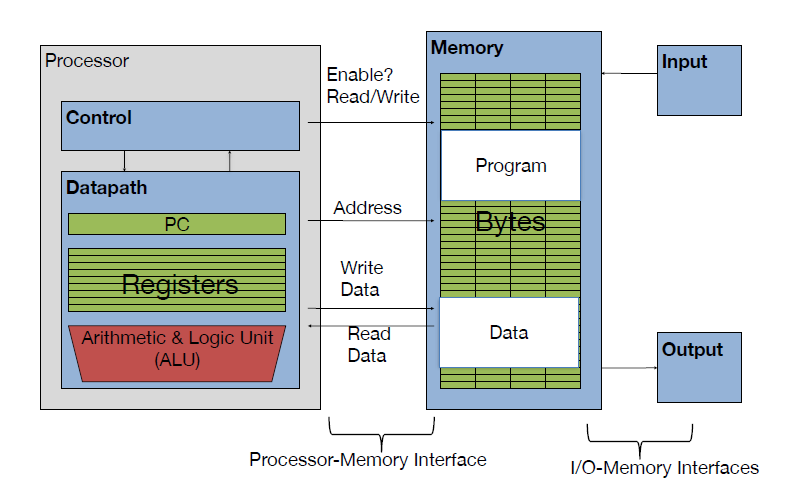
我们可以从中看到在 CPU 需要运行一个进程的时候,首先会将指令告诉主存(main memory), 然后开始在主存中找地址(Address)找到后加载到在 CPU 内部通用寄存器(register)然后开始执行 执行完后再写入主存中。
<p>在这里面还有一个步骤,memory 要先向 disk 中读取数据</p>
其实现实中,CPU 通用寄存器的速度和主存之间存在着太大的差异。两者之间的速度大致如下关系:
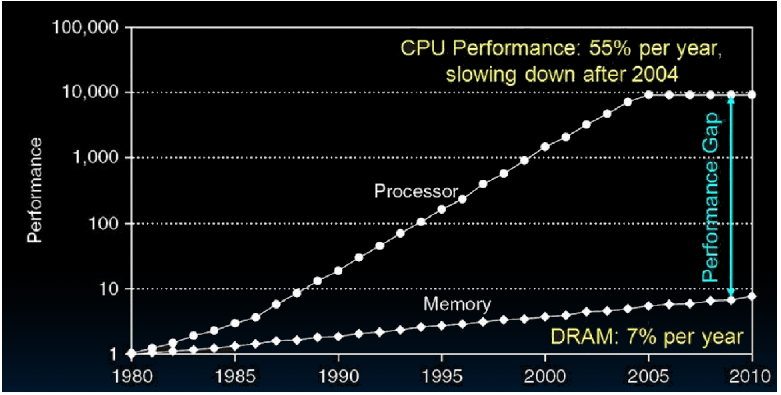
Oh!!! 它们相差 1,000 倍左右,这是无法想像的,就比如当我前 1 ns 的时候 CPU 已经做完了,而我还要等 1000 ns 的 memory 的时间,因此在我们看来 CPU 此时是空闲的,大大的浪费了。
因此,如果我们可以提升主存的速度,那么对于系统来说将会获得很大的性能提升。但我们试图提升主存的速度和容量,又期望其成本很低,这就有点难为人了。因此,我们有一种折中的方法,那就是制作一块速度极快但是容量极小的存储设备。那么其成本也不会太高。这块存储设备我们称之为 cache。在硬件上,我们将 cache 放置在 CPU 和 主存 之间,作为主存数据的缓存。当 CPU 试图从主存中 load/store 数据的时候, CPU 会首先从 cache 中查找对应地址的数据是否缓存在 cache 中。如果其数据缓存在 cache 中,直接从 cache 中拿到数据并返回给 CPU。
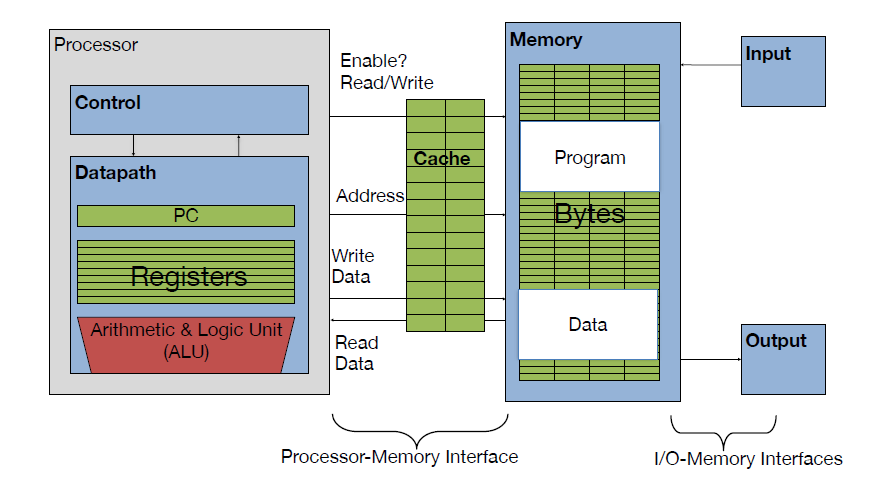
其实类比的话,我蛮喜欢 CS 61 c 里面的 Library Analogy,而我自己的想法是有点像现在的物流运输:对一些物品都有一个 主要的仓库,而也有一些 本地仓,当我要送东西的时候我先去看看 本地仓 有没有,没有就再去 主仓 去看看,但时间上就没有本地仓的快
<p>[[2. Areas/01 Blog/03-ComputerSystems/cs61c/SRAM vs. DRAM vs. Disk]]</p>
Memory Hierarchy
好的现在我们知道了 cache 的出现了,而下面的图是说明了对于不同的内存级别
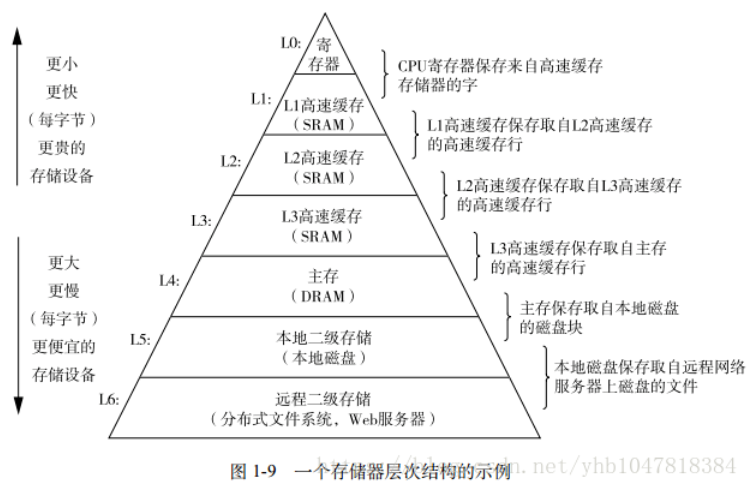
Cache
Cache 的级别
<p>每一级的 cache 就是每一个下级内存的副本</p>
Cahe 的速度在一定程度上同样影响着系统的性能. 当 cache 中没有缓存我们想要的数据的时候,依然需要漫长的等待从主存中 load 数据。为了进一步提升性能,引入多级 cache。前面提到的 cache,称之为 L 1 cache(第一级 cache)。我们在 L 1 cache 后面连接 L 2 cache,在 L 2 cache 和主存之间连接 L 3 cache。等级越高,速度越慢,容量越大。
Temporal Locality (时间局部性)
<p>If a memory location is referenced then it will tend to be referenced again soon</p>
比如说我用过一次这个地址, 我保存起来以防我下次使用
Spatial Locality (空间局部性)
<p>If a memory location is referenced, the locations with nearby addresses will Tend to be referenced soon</p>
比如一个数组,在我读取的时候它会把数组左右的都读取了
Cache Hit vs Cache Miss
在我要对数据进行查找的时候会出现两种情况 Cache Hit & Cache Miss.
Cache hit
你要查找的数据 在缓存中 从缓存中检索数据并将其带到处理器.
Cache miss
你要查找的数据 不在缓存中 去内存中找数据,把数据放到缓存中,带到处理器中
Cache 的工作原理
现在我们来继续说一些快取的工作原理, 在此之前先来说一下的一些名词
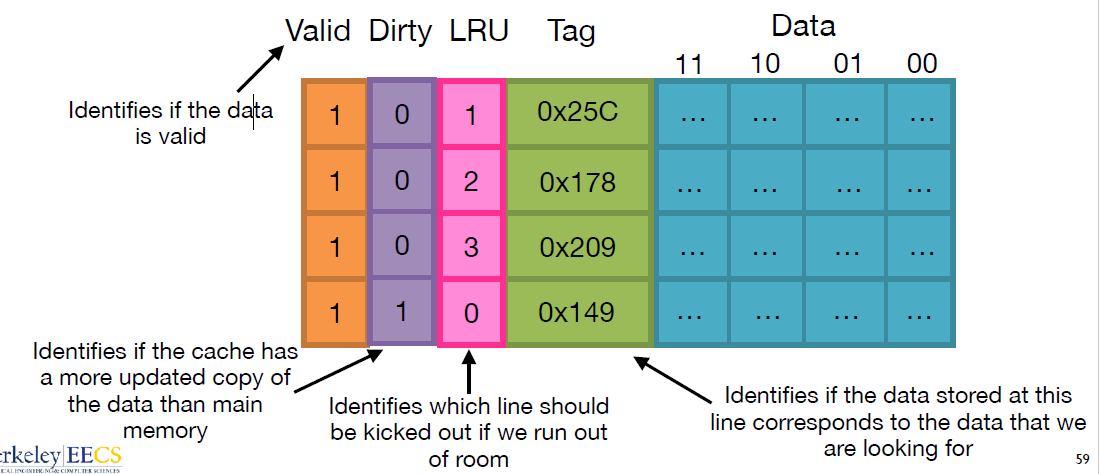
什么是 line/tag/index/offset/valid
- line: 我们将 cache 平均分成相等的很多块,每一个块大小称之为
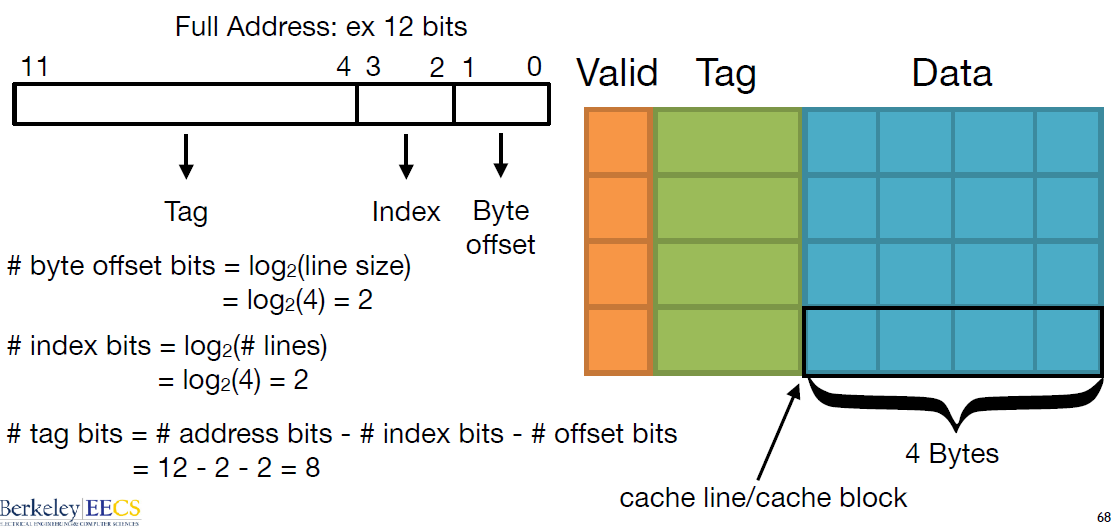
cache line也可以叫cache block,其大小是cache line size。 - tag: Used to identify the data (用于识别数据)。每条 Cache Line 前都会有一个独立分配的内存来存 tag,其就是内存地址的前 Nbits。 $$ addressbits - offsetbits $$
- offset: Identifies the byte offset (标识字节偏移量)。一般是低位后几位。 $$ offset = log_2(line size) $$
- index: 内存地址后续的 bits 则是在这–Way 的是 Cache Line 索引,可以索引 Cache Line。
- Valid bit: Tells you if the data stored at a given cache line is valid (告诉您存储在给定缓存行中的数据是否有效)
<p>一个地址访问要映射到 Cache 中,地址被分成三个字段:tag,set index, block offset。这样,通过一个物理地址就可以获取数据或指令在缓存中的位置 (set, way, byte))</p>
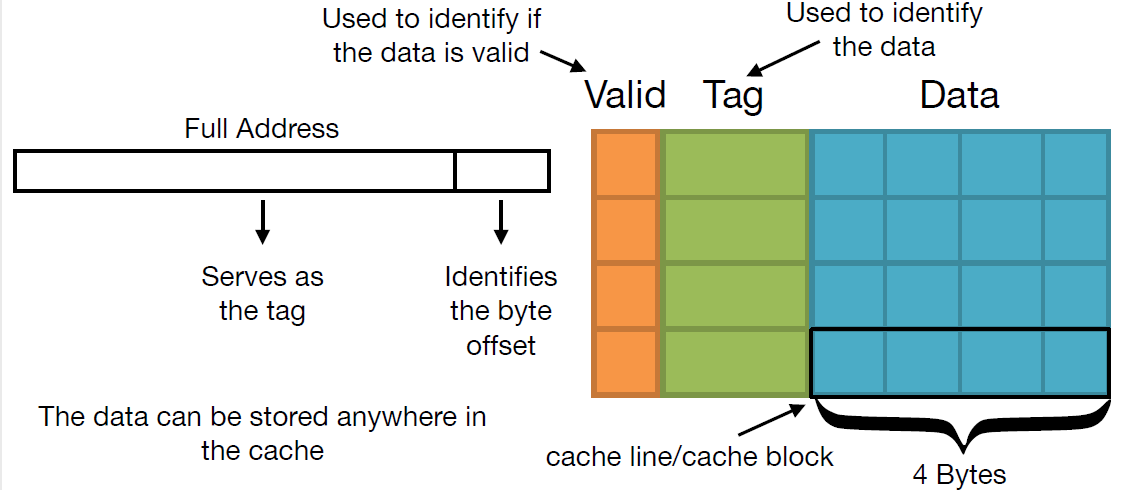
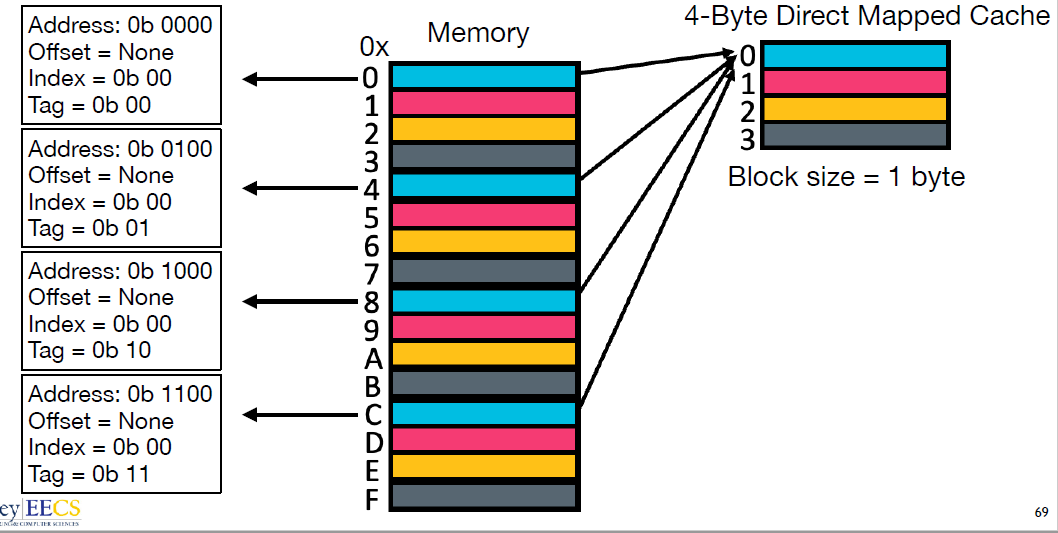
Direct mapped cache (直接映射缓存)
优点:直接映射缓存在硬件设计上会更加简单,因此成本上也会较低。
<p>一句话, 我一个个的加载进入 cache, 当我的 cache 满了我就转头再来一遍</p>
<p>只适合于<strong>大容量</strong>Cache</p>
缺点: 继续访问下面的地址时,依然会 cache 缺失。这就相当于每次访问数据都要从主存中读取,所以 cache 的存在并没有对性能提升有效, 有 cache颠簸 (每个主存块只有一个固定位置可存放,容易产生冲突)
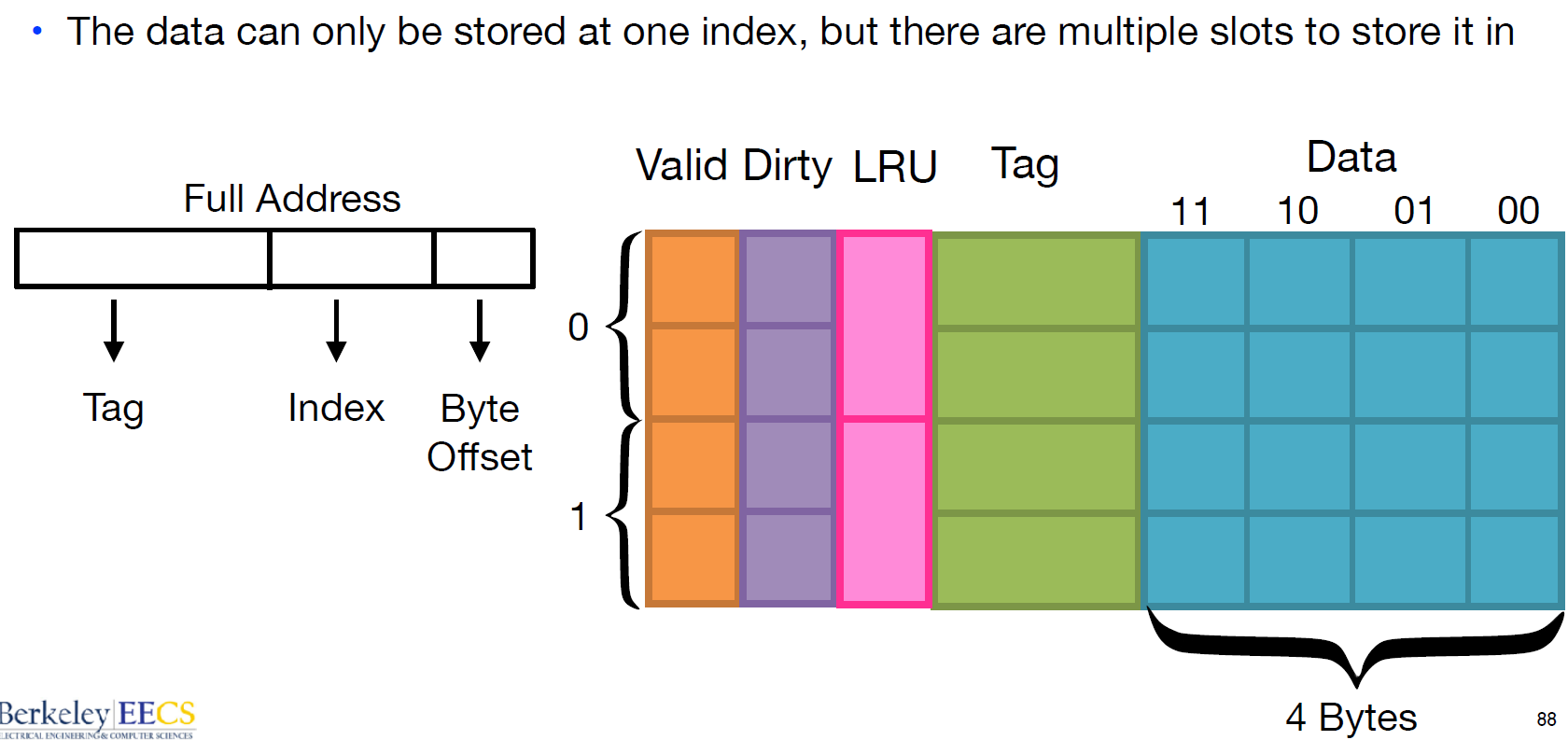
Two-way set associative cache (两路组相连缓存)
Cache 分了 2 组
优点: 减少 cache 颠簸出现频率
<p>组相联映射实际上是直接映射和全相联映射的折中方案</p>
缺点: 增加硬件设计复杂读、成本较高 (需要比较多个 cache line 的 TAG)
Fully Associative Cache (全相连缓存)
优点: 最大程度的降低 cache 颠簸的频率
<p>只适合于<strong>小容量</strong>Cache</p>
缺点: 增加硬件设计复杂读、成本较高 (需要比较多个 cache line 的 TAG)
扩展:[[More Eviction Policies]]

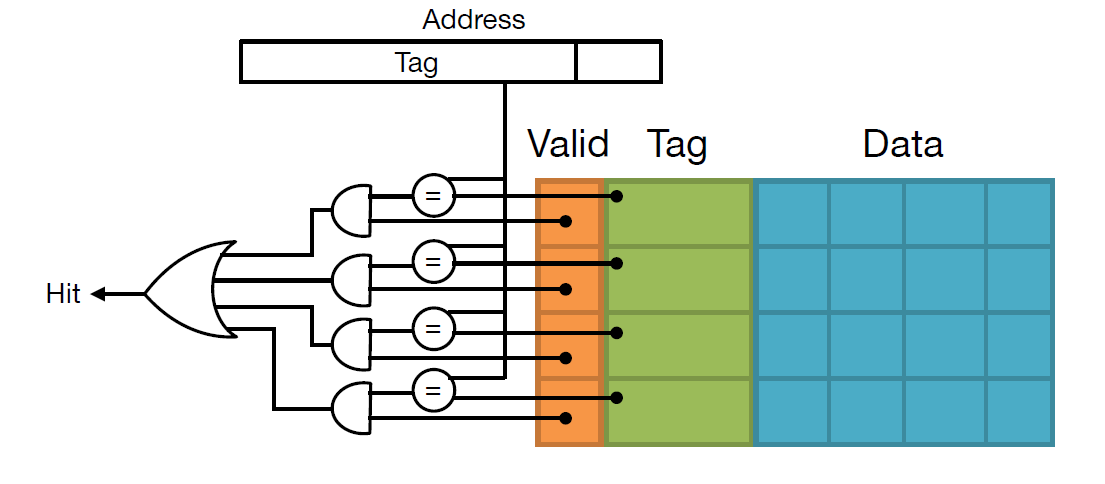
寻找 Hit 的电路
[[Types of Misses]]

Comparisons
三个 cache 的区别之分
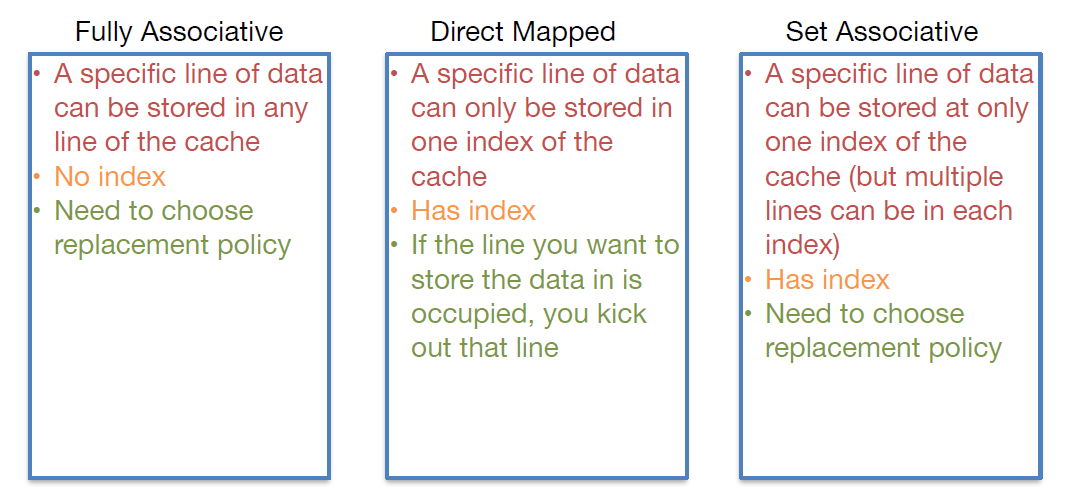 需补充
需补充