XV6的文件系统
<p>上帝说要保存世界,于是有了文件系统</p>
我们之前都是在研究内存和 CPU 上的工作,对于它们而言只有在接通了电源时才可以使用,断电后就清除数据了。尤其是其中的随机存取存储器(RAM)芯片和 CPU 内存缓存(L1、L2和 L3 等)。因此我们急需一个可以永久保存数据的地方,一般这种 big 问题 都是优先有硬件来改变的,磁盘就出现了,它用来“永久”的保存数据。而新的问题就出现了,我怎么从磁盘中找寻、读取、存储数据呢?这就来看操作系统的文件管理系统的工作了。
磁盘 (Disk)
磁盘是一种利用 磁记录技术 来实现存储的存储设备。磁记录技术利用磁性颗粒的磁化来保存数据。磁盘通常由一个或多个磁性盘组成,这些盘可以旋转。数据存储在盘片的表面上,而读写头则负责在盘片上读写数据。
磁盘的工作原理涉及到磁性颗粒的磁化和读写头的操作。当数据写入磁盘时,读写头会改变磁性颗粒的磁化方向,从而记录数据。而当需要读取数据时,读写头会扫描磁盘表面,通过检测磁性颗粒的磁化方向来读取数据。
<p>磁盘是对内存而言的存储设备,所以有时也叫<strong>辅存</strong> 。</p>
物理结构
想要了解磁盘的存储就要稍稍知道点磁盘的物理结构 : 硬盘的物理结构一般由磁头与盘片、电动机、主控芯片与排线等部件组成;当主电动机带动盘片旋转时,副电动机带动一组(磁头)到相对应的盘片上并确定读取正面还是反面的碟面,磁头悬浮在碟面上画出一个与盘片同心的圆形轨道(磁道或称柱面),这时由磁头的磁感线圈感应碟面上的磁性与使用硬盘厂商指定的读取时间或数据间隔定位扇区,从而得到该扇区的数据内容;
- 盘片(Platters):磁盘中的盘片是类似于圆盘的结构,它们堆叠在一起并存储数据。
- 磁头(Head):磁头是安装在硬盘驱动器臂上的设备,用于在磁盘的表面上读取或写入数据。
- 主轴(Spindle):主轴是一个旋转的轴,用于将盘片固定在一个位置,以便读/写臂能够在盘片上获取数据。
- 执行器(Actuator):执行器由读写头组成,它在硬盘上移动以保存或检索信息。
- 柱面(Cylinder):这些是磁盘驱动器盘片上的圆形轨道,与磁盘中心的距离相等。
- 扇区(Sector):盘上的每个磁道被等分为若干个弧段,这些弧段便是硬盘的扇区。硬盘的第一个扇区,叫做引导扇区。
<p><strong>sectors</strong> 和 <strong>blocks</strong>。</p>
- sector通常是磁盘驱动可以读写的最小单元,它过去通常是512字节。
- block通常是操作系统或者文件系统视角的数据。它由文件系统定义,在 XV 6 中它是 1024 字节。所以 XV 6 中一个 block 对应两个 sector。通常来说一个 block 对应了一个或者多个 sector。
工作方式
当硬盘读取数据时,磁头会感知盘片上的磁场,并将其转换为电信号,然后传输到计算机中。当硬盘写入数据时,磁头会通过电信号改变盘片上的磁场,从而实现数据的存储。这个过程是通过磁头在盘片上移动,根据需要读取或写入数据来完成的。
随着科技的发展,现在不满足硬盘的速度和空间大小了,我们有新的磁盘:固态硬盘(SSD)是一种新型磁盘,它采用闪存存储技术,具有更快的读写速度和更大的存储容量。
xv6
对于文件系统必须有将索引节点和内容块存储在磁盘上具体位置的方案。为此,xv6将磁盘划分为几个部分,文件系统不使用块0(它保存引导扇区)。块1称为超级块:它包含有关文件系统的元数据(文件系统大小(以块为单位)、数据块数、索引节点数和日志中的块数)。从2开始的块保存日志。日志之后是索引节点,每个块有多个索引节点。然后是位图块,跟踪正在使用的数据块。其余的块是数据块:每个都要么在位图块中标记为空闲,要么保存文件或目录的内容。超级块由一个名为 mkfs 的单独的程序填充,该程序构建初始文件系统。
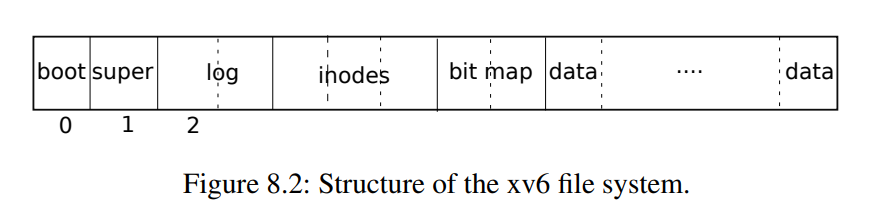 通常来说,
通常来说,bitmap block,inode blocks和log blocks被统称为metadata block。它们虽然不存储实际的数据,但是它们存储了能帮助文件系统完成工作的元数据。
在继续下面的内容时,要提出几点问题:
- 文件系统怎么在磁盘上来表示数据?
- 当系统出现崩溃时要怎么恢复?怎么保证 crash safety?
- 辅存在性能上是
ms级的,我怎么提高性能?
缓冲区高速缓存 (Buffer cache)
Buffer cache,这是为了解决磁盘到内存的性能问题和确保两个及其以上的进程不会互相影响而设计的。 它主要有两个任务:
- 同步对磁盘块的访问,以确保磁盘块在内存中只有一个副本,并且一次只有一个内核线程使用该副本
- 缓存常用块,以便不需要从慢速磁盘重新读取它们。
struct {
struct spinlock lock;
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
struct buf head;
} bcache;在其中, buf 数据结构就是一个 block
struct buf {
int valid; // has data been read from disk?
int disk; // does disk "own" buf?
uint dev;
uint blockno;
struct sleeplock lock;
uint refcnt;
struct buf *prev; // LRU cache list
struct buf *next;
uchar data[BSIZE];
};Buffer cache 层主要接口是 bread 和 bwrite;前者从 cache 中获取一个 buf,其中包含一个可以在内存中读取或修改的块的副本;后者将修改后的缓冲区写入磁盘上的相应块。可以说 Buffer cache 在内存中。而内核线程必须通过调用 brelse 释放缓冲区。Buffer cache 每个缓冲区使用一个 sleep lock,保证每个缓冲区每次只被一个线程使用。bread 返回一个上锁的缓冲区,brelse 释放该锁。
在 Buffer cache 中,保存磁盘块的缓冲区数量是固定,说明如果文件系统请求并还未存放在缓存中的块多出固定值,那么 Buffer cache 必须回收当前保存其他块旧内容的缓冲区。Buffer cache 使用的是 LRU 回收机制。这样做的原因是认为最近使用最少的缓冲区是最不可能近期再次使用的缓冲区。
来看看 bread 和 bwrite 的实现
// Return a locked buf with the contents of the indicated block.
struct buf*
bread(uint dev, uint blockno)
{
struct buf *b;
b = bget(dev, blockno);
if(!b->valid) {
virtio_disk_rw(b, 0);
b->valid = 1;
}
return b;
}bread函数首先会调用bget函数,bget会为我们从buffer cache中找到block的缓存。
// Look through buffer cache for block on device dev.
// If not found, allocate a buffer.
// In either case, return locked buffer.
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
acquire(&bcache.lock);
// Is the block already cached?
for(b = bcache.head.next; b != &bcache.head; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
// Not cached.
// Recycle the least recently used (LRU) unused buffer.
for(b = bcache.head.prev; b != &bcache.head; b = b->prev){
if(b->refcnt == 0) {
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
panic("bget: no buffers");
}这个 bget 的实现就是一个双链的向前遍历寻找指定、向后遍历寻找空位。
其中,如果有多个进程同时调用 bget 的话,其中一个可以获取 bcache 的锁并扫描 buffer cache。此时,其他进程是没有办法修改 buffer cache 的。之后,进程会查找 block number 是否在 cache 中,如果在的话将 block cache 的引用计数(refcnt)加1,表明当前进程对 block cache 有引用,之后再释放 bcache 的锁。如果有第二个进程也想扫描 buffer cache,那么这时它就可以获取 bcache 的锁。假设第二个进程也要获取 block 33的 cache,那么它也会对相应的 block cache 的引用计数加1。最后这两个进程都会尝试对 block 33的 block cache 调用 acquiresleep 函数。所以说在 xv6 中对 buffer cache 做任何修改的话,都必须持有 bcache 的锁;其次对单个 block 的 cache 做任何修改你需要持有该 block 的 sleep lock。
而 bwrite 仅仅是为了将有锁块的内容写入到 virio disk 中。
void
bwrite(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("bwrite");
virtio_disk_rw(b, 1);
}brelse 是在线程结束对 block 的操作时使用。
// Release a locked buffer.
// Move to the head of the most-recently-used list.
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
acquire(&bcache.lock);
b->refcnt--;
if (b->refcnt == 0) {
// no one is waiting for it.
b->next->prev = b->prev;
b->prev->next = b->next;
b->next = bcache.head.next;
b->prev = &bcache.head;
bcache.head.next->prev = b;
bcache.head.next = b;
}
release(&bcache.lock);
}当调用方使用完缓冲区后,它必须调用 brelse 来释放回收缓冲区。brelse 释放 sleep lock 并将缓冲区移动到链表的前面。移动缓冲区会使列表按缓冲区的使用频率排序:列表中的第一个缓冲区是最近使用的,最后一个是最近使用最少的。bget 中的两个循环利用了这一点:在最坏的情况下,对现有缓冲区的扫描必须处理整个列表,但首先检查最新使用的缓冲区(从 bcache.head 开始,然后是下一个指针),在引用局部性良好的情况下将减少扫描时间。
block cache的实现,这对于性能来说是至关重要的,因为读写磁盘是代价较高的操作,可能要消耗数百毫秒,而block cache确保了如果我们最近从磁盘读取了一个block,那么我们将不会再从磁盘读取相同的block。
日志 (Logging)
log ,操作系统最重要的一环,为保证 crash safety 而设计的机制。在使用机器中我们最担心出现的情况就是 crash 或者电力故障等可能会导致在磁盘上的文件系统处于不一致或者不正确状态的问题。而为了确保系统安全,要有可以阻止问题发生或修复的机制。 logging。这是一个最初来自于数据库世界的很流行的解决方案,现在很多文件系统都在使用 logging。之所以它很流行,是因为它是一个很好用的方法。接下来将会看到在 XV6中的简单 logging 实现。其中也包含了一些微妙的问题,讨论问题,解决问题。这也是为什么文件系统的 logging 值得学习的原因。
- 首先,它可以确保文件系统的系统调用是原子性的。比如你调用 create/write 系统调用,这些系统调用的效果是要么完全出现,要么完全不出现,这样就避免了一个系统调用只有部分写磁盘操作出现在磁盘上.
- 其次,它支持快速恢复(Fast Recovery)。在重启之后,我们不需要做大量的工作来修复文件系统,只需要非常小的工作量。这里的快速是相比另一个解决方案来说,在另一个解决方案中,你可能需要读取文件系统的所有block,读取inode,bitmap block,并检查文件系统是否还在一个正确的状态,再来修复。而logging可以有快速恢复的属性。
- 最后,原则上来说,它可以非常的高效,尽管我们在XV6中看到的实现不是很高效。
先来想想,如果要对某文件做写操作一般的过程是怎么样的。
- 创建该文件
- 找一个空闲的 inode 并更新 inode 的数据。
- 在 bit map 中找到当前目录的 data block 把 inode 加进去,告诉目录有新的数据。
- 再次更新了文件的 inode 。
- 写入数据
- 通过扫描 bitmap 找到一个还没有使用的 data block ,返回从 date blocks 中找到新地址。
- 在 xv 6 中一次可以写入一个字节的数据,也就是一个字符,所以有几个字符就调用几次新的 data block。
- 最后更新文件的 inode 的大小等信息。
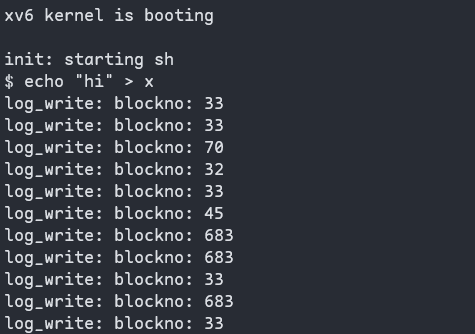 这样看来数据流是从 memory 到 block cache 再到dick,log 在哪里?其实当我们在内存中缓存了bitmap block,假设写 block 45。当需要更新 bitmap 时,我们并不是直接写 block ,而是将数据写入到 log 中,并记录这个更新应该写入到 block 70。对于所有的写 block 都会有相同的操作,例如更新 inode,也会记录一条写 block 33 的 log。所以说 log 出现在要写入 block 的前面。
然后,在某个时间点,当文件系统的操作结束了,比如说我们前一节看到的4-5个写 block 操作都结束,并且都存在于 log 中,我们会 commit 文件系统的操作。这意味着我们需要在 log 的某个位置记录属于同一个文件系统的操作的个数,例如5。
之后当我们在 log 中存储了所有写 block 的内容时,如果我们要真正执行写入 dick 的操作,只需要将 block 从 log 分区移到文件系统分区。我们知道第一个操作该写入到 block 45,我们会直接将数据从 log 写到 block45,第二个操作该写入到 block 33,我们会将它写入到 block 33,依次类推。
最后,一旦完成了,就可以清除 log。清除 log 实际上就是将属于同一个文件系统的操作的个数设置为0。
这样看来数据流是从 memory 到 block cache 再到dick,log 在哪里?其实当我们在内存中缓存了bitmap block,假设写 block 45。当需要更新 bitmap 时,我们并不是直接写 block ,而是将数据写入到 log 中,并记录这个更新应该写入到 block 70。对于所有的写 block 都会有相同的操作,例如更新 inode,也会记录一条写 block 33 的 log。所以说 log 出现在要写入 block 的前面。
然后,在某个时间点,当文件系统的操作结束了,比如说我们前一节看到的4-5个写 block 操作都结束,并且都存在于 log 中,我们会 commit 文件系统的操作。这意味着我们需要在 log 的某个位置记录属于同一个文件系统的操作的个数,例如5。
之后当我们在 log 中存储了所有写 block 的内容时,如果我们要真正执行写入 dick 的操作,只需要将 block 从 log 分区移到文件系统分区。我们知道第一个操作该写入到 block 45,我们会直接将数据从 log 写到 block45,第二个操作该写入到 block 33,我们会将它写入到 block 33,依次类推。
最后,一旦完成了,就可以清除 log。清除 log 实际上就是将属于同一个文件系统的操作的个数设置为0。
log 的基本工作方式。
- Log write
- Commit op
- Install log
- Clean log 假设我们 crash 并重启了。在重启的时候,文件系统会查看 log 的 commit 记录值,如果是0的话,那么什么也不做。如果大于0的话,我们就知道 log 中存储的 block 需要被写入到文件系统中,很明显我们在 crash 的时候并不一定完成了 install log,我们可能是在 commit 之后,clean log 之前 crash 的。所以这个时候我们需要做的就是 reinstall(注,也就是将 log 中的 block 再次写入到文件系统),再 clean log。
接下来看看 XV6 中的 log 结构:
struct log {
struct spinlock lock;
int start;
int size;
int outstanding; // how many FS sys calls are executing.
int committing; // in commit(), please wait.
int dev;
struct logheader lh;
};这里有一个 logheader 其实就是 log block 的 head ,长这样的:
struct logheader {
int n; // 数字n代表有效的log block的数量
int block[LOGSIZE]; // 每个log block的实际对应的block编号 如 45、33
};最后看看怎么使用 log 在系统调用中一个典型的 log 使用就像这样:
begin_op();
...
bp = bread(...);
bp->data[...] = ...;
log_write(bp);
...
end_op();一个事务transaction 以 begin_op 表示开始和 end_op 表示结束。并且其中的事务所有写 block 操作具备原子性,这意味着这些写 block 操作要么全写入,要么全不写入。
在 begin_op 和 end_op 之间,磁盘上或者内存中的数据结构会更新。但是在 end_op 之前,并不会有实际的改变(也就是不会写入到实际的 block 中)。在 end_op 时,我们会将数据写入到 log 中,之后再写入 commit record 或者 log header。这里有趣的是,当文件系统调用执行写磁盘时会发生什么?
log_write 是由文件系统的 logging 实现的方法。任何一个文件系统调用的 begin_op 和 end_op 之间的写操作总是会走到 log_write。log_write 函数位于log.c 文件。其中,文件系统中的所有 bwrite 都需要被 log_write 替换
void
log_write(struct buf *b)
{
int i;
acquire(&log.lock);
if (log.lh.n >= LOGSIZE || log.lh.n >= log.size - 1)
panic("too big a transaction");
if (log.outstanding < 1)
panic("log_write outside of trans");
for (i = 0; i < log.lh.n; i++) {
if (log.lh.block[i] == b->blockno) // log absorption
break;
}
log.lh.block[i] = b->blockno;
if (i == log.lh.n) { // Add new block to log?
bpin(b);
log.lh.n++;
}
printf("log_write: blockno: %d\n", b->blockno);
// printf("log_write: log.lh.n: %d\n", log.lh.n);
// printf("log_write: log.committing: %d\n", log.committing);
release(&log.lock);
}接下来看一下发生在 XV6 的启动过程中的文件系统的恢复流程。当系统 crash 并重启了,在 XV6启动过程中做的一件事情就是调用 initlog 函数。
void
initlog(int dev, struct superblock *sb)
{
if (sizeof(struct logheader) >= BSIZE)
panic("initlog: too big logheader");
initlock(&log.lock, "log");
log.start = sb->logstart;
log.size = sb->nlog;
log.dev = dev;
recover_from_log();
}static void
recover_from_log(void)
{
read_head();
install_trans(1); // if committed, copy from log to disk
log.lh.n = 0;
write_head(); // clear the log
}recover_from_log 先调用 read_head 函数从磁盘中读取 header,之后调用 install_trans 函数。这个函数之前在 commit 函数中也调用过,它就是读取 log header 中的 n,然后根据 n 将所有的 log block 拷贝到文件系统的 block 中。recover_from_log 在最后也会跟之前一样清除 log。
这就是恢复的全部流程。如果我们在install_trans 函数中又 crash 了,也不会有问题,因为之后再重启时,XV6会再次调用 initlog 函数,再调用 recover_from_log 来重新 install log。如果我们在 commit 之前 crash 了多次,在最终成功 commit 时,log 可能会 install 多次。
(其他问题暂定)
log 和 cache 的区别
- Log(日志):日志是用于记录系统运行状态、事件和操作的记录。它通常用于故障排查、监控系统运行情况以及追踪用户操作等方面。日志文件可以包含系统错误、警告、信息等不同级别的记录,有助于系统管理员或开发人员了解系统的运行状况
- Cache(缓存):缓存是一种高速数据存储层,用于临时存储数据,通常是暂时性的。缓存被用来存储最近或频繁访问的数据,以提高数据访问速度。它是一种小型、更快速、更昂贵的内存,用于改善最近或频繁访问的数据的性能。缓存通常被CPU、应用程序、Web浏览器和操作系统使用,以减少数据访问时间、降低延迟并改善输入/输出性能