XV6的进程和线程
<p>看我影分身之术!</p>
我将进程和线程放在一起写就是因为它们两个是表兄弟 ,这两个东东可以说是我不好区分的事,在之前我利用 AI 来尝试理解— [[进程(Process)和 线程(Thread)]] — 过于笼统,因此我要自己通过 XV6 来理解。
进程
进程是对于计算机中运行的程序的对象。它包括了程序的代码、数据、执行状态以及系统资源的拷贝,如内存空间、文件等。
操作系统通过对进程的管理来具象的调度程序,进程也对于将 User Space 和 Kernel Space 有隔离提供帮助,如,内存的虚拟 — 每个进程有自己的页表。如果把 CPU 看成一个巨大的工厂,那么进程在其中充当的是某产品的完整生产路径,它拥有许多的工人、原料、某流水线、打包等。而其中它与其它产品没关系(至少没有直接关系)。
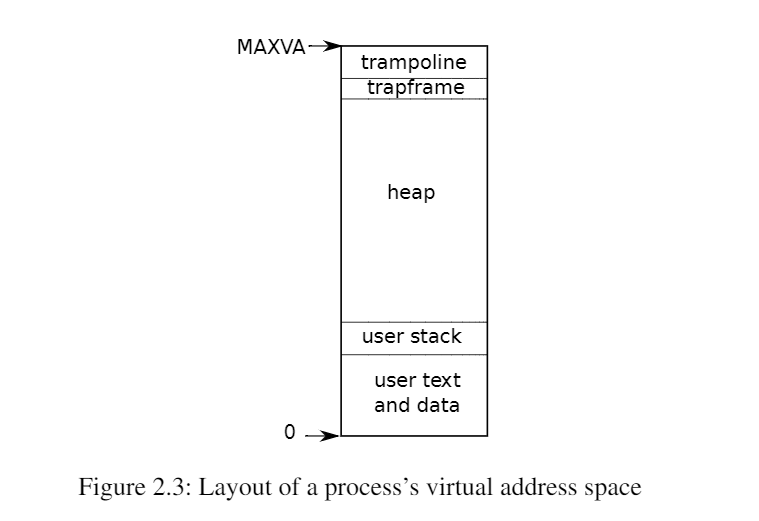 一个进程需要的空间
一个进程需要的空间
对于操作系统来说进程就是数据结构,看看在 XV6 中的 proc.h
// Per-process state
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// wait_lock must be held when using this:
struct proc *parent; // Parent process
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
struct trapframe *trapframe; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};很复杂,在真正的系统中会更加的复杂和多样。
其中,enum procstate state; 进程的状态(有些是线程的)
enum procstate { UNUSED, USED, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };简单讲有以下几种:
- 运行(running):在运行状态下,进程正在处理器上运行。这意味着它正在执行指令。
- 就绪(ready):在就绪状态下,进程已准备好运行,但由于某种原因,操作系统选择不在此时运行。
- 阻塞(blocked):在阻塞状态下,一个进程执行了某种操作,直到发生其他事件时才会准备运行。一个常见的例子是,当进程向磁盘发起 I/O 请求时,它会被阻塞,因此其他进程可以使用处理器。 还有一个特殊的:
- ZOMBIE (僵尸): “僵尸状态"是指一个进程已经终止执行,但其父进程尚未对其进行善后处理,导致其在进程表中仍然保留着。这种状态下的进程被称为"僵尸进程”。僵尸进程不再执行任何指令,但其进程表项仍然占用系统资源。通常情况下,父进程应该调用
wait()或waitpid()函数来回收僵尸进程,释放其占用的资源。
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
这些都是进程的属性。
struct proc *parent; // Parent process
在 fork() 中可能会有父进程。init 进程是所有进程的 parent
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
struct trapframe *trapframe; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
这些就是在系统中可以怎么做产品的具体原料、流水线了。
但是我们在 CPU 中不是一直做一个进程的,进程间需要交换而进程之间的交换就是线程之间的交换 。
线程
线程可以认为是一种在有多个任务时简化编程的抽象。一个线程可以认为是串行执行代码的单元。如果你写了一个程序只是按顺序执行代码,那么你可以认为这个程序就是个单线程程序,这是对于线程的一种宽松的定义。虽然人们对于线程有很多不同的定义,在这里,我们认为线程就是单个串行执行代码的单元,它只占用一个 CPU 并且以普通的方式一个接一个的执行指令。
再次来到我的工厂里面,如果进程完整生产路径,那么线程就是这条路径上的最小单位 — 一条流水线的工作— 有相应的属性。这里其实我把 RISC-V 里面的流水线结构用上了,想想看一条流水线上有一个线程在运行,所以我叫它—流水线的工作。
值得一提的,我们可以随时保存线程的属性并暂停线程的运行,并在之后通过恢复属性来恢复线程的运行。线程的属性包含了三个部分:
- 程序计数器(Program Counter),它表示当前线程执行指令的位置。
- 保存变量的寄存器。
- 程序的 Stack。通常来说每个线程都有属于自己的 Stack,Stack 记录了函数调用的记录,并反映了当前线程的执行点。
线程是用来实现多进程的并行运行的具体,我们为了提高速率就让进程可以不停止的运动,因此就把线程用来执行分时复用的任务,有一个进程停了就切换另一个。
而让线程可以的并行运行主要有两个策略:
- 第一个策略,在多核处理器上使用多个 CPU,每个 CPU 都可以运行一个线程。如果你有4个 CPU,那么每个 CPU 可以运行一个线程。每个线程自动的根据所在 CPU 就有了程序计数器和寄存器。但是如果你只有4个 CPU,却有上千个线程,每个 CPU 只运行一个线程就不能解决这里的问题了。
- 第二个策略,让一个 CPU 在多个线程之间来回切换。假设我只有一个 CPU,但是有1000个线程,先运行一个线程,之后将线程的状态保存,再切换至运行第二个线程,然后再是第三个线程,依次类推直到每个线程都运行了一会,再回来重新执行第一个线程。
<p>我的 cpu 就 8 核,但有六千多的 Threads。</p>
那么这里有一个问题,一个进程可以有多少线程?
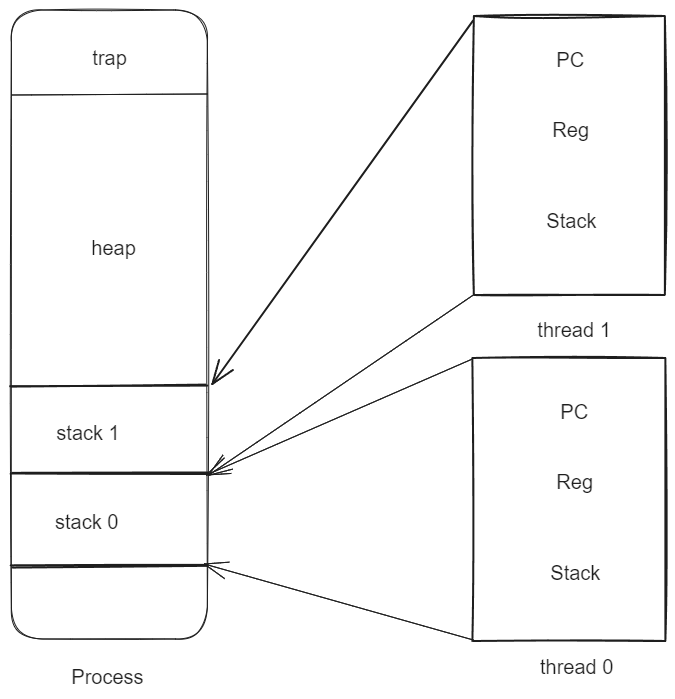
在 XV6 中一个进程有两个线程:
- User Thread: 每一个用户进程都有独立的内存地址空间,并且包含了一个线程,这个线程控制了用户进程代码指令的执行。
- Kernel Thread : 对于每个用户进程都有一个内核线程来执行来自用户进程的系统调用。所有的内核线程都共享了内核内存,所以XV6的内核线程的确会共享内存。
如果 XV 6 内核决定从一个用户进程切换到另一个用户进程,那么首先在内核中第一个进程的内核线程会被切换到第二个进程的内核线程。之后再在第二个进程的内核线程中返回到用户空间的第二个进程,这里返回也是通过恢复 trapframe 中保存的用户进程状态完成。
这里核心点在于,在 XV6中,任何时候都需要经历:
- 从一个用户进程切换到另一个用户进程,都需要从第一个用户进程接入到内核中,保存用户进程的状态并运行第一个用户进程的内核线程。
- 再从第一个用户进程的内核线程切换到第二个用户进程的内核线程。
- 之后,第二个用户进程的内核线程暂停自己,并恢复第二个用户进程的用户寄存器。
- 最后返回到第二个用户进程继续执行。
通常说的是从一个线程切换到另一个线程,因为在切换的过程中需要先保存前一个线程的寄存器,然后再恢复之前保存的最后一个线程的寄存器。
线程状态
- RUNNING,线程当前正在某个CPU上运行
- RUNABLE,线程还没有在某个CPU上运行,但是一旦有空闲的CPU就可以运行
- SLEEPING,这个状态意味着线程在等待一些 I/O 事件,它只会在 I/O 事件发生了之后运行
<p>这里不同的线程是由状态区分,但是实际上线程的完整状态会要复杂的多。</p>
XV6 线程切换
实际上的线程切换顺序更像这样:
- 一个进程出于某种原因想要进入休眠状态,比如说出让 CPU 或者等待据,它会先获取自己的锁;
- 之后进程将自己的状态从 RUNNING 设置为 RUNNABLE;
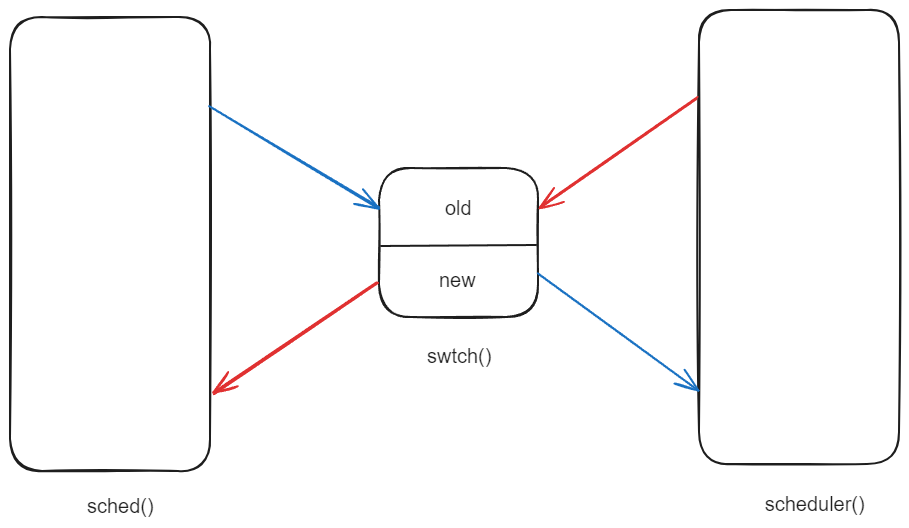
- 之后进程调用 switch 函数,其实是调用 sched 函数在 sched 函数中再调用的 switch 函数;
- switch 函数将当前的线程切换到调度器线程;
- 调度器线程之前也调用了 switch 函数,现在恢复执行会从自己的 switch 函数返回;
- 返回之后,调度器线程会释放刚刚出让了 CPU 的进程的锁
接下来我们以 CPU 作为一个参照物来理解线程切换,现在带着几个问题:
- 线程为什么切换?
- 线程是怎么切换?
- 线程切换要保存什么?
开始
假设我们有两个 CPU — CPU0、CPU1,CPU0 正在运行一个进程——shell ——这个用户程序在运行时,实际上是其中的用户线程在运行,此时我想运行另一个进程—ls ,CPU0 会进入 trap —— 通过系统调用、定时器中断、I/O 中断 —— 同时属于这个用户程序的内核线程被激活,CPU0 使用来自内核线程的stack,而现在如果 XV6内核决定从一个用户进程切换到另一个用户进程,那么首先在内核中第一个进程的内核线程会被切换到第二个进程的内核线程。
而在 xv6 的代码实现中(用定时器中断举例),我会进入 yield() 函数,是一个放弃当前 CPU 的函数
// Give up the CPU for one scheduling round.
void
yield(void)
{
struct proc *p = myproc();
acquire(&p->lock);
p->state = RUNNABLE;
sched();
release(&p->lock);
}进入到 yield() 后取得当前进程的锁也就是shell 改变它的状态为RUNNABLE ,这里有个奇怪的地方,我们不是在对线程改状态吗,为什么是改变了进程的状态? 我个人认为这是因为在 xv6 中一个进程只有一个用户线程,所以就把线程的状态放在进程里面。然后最重要的线程调度来了。
sched () 函数实际上就是将一个 RUNNING 线程转换成一个 RUNNABLE 线程的过程。所以对于每一个 RUNNABLE 线程,当我们将它从 RUNNING 转变成 RUNABLE 时,我们需要将之前位于 CPU0 的信息也就是 PC 和寄存器拷贝到内存中的某个位置,注意这里不是从内存中的某处进行拷贝,而是从 CPU 中的寄存器拷贝。
void
sched(void)
{
int intena;
struct proc *p = myproc();
if(!holding(&p->lock))
panic("sched p->lock");
if(mycpu()->noff != 1)
panic("sched locks");
if(p->state == RUNNING)
panic("sched running");
if(intr_get())
panic("sched interruptible");
intena = mycpu()->intena;
swtch(&p->context, &mycpu()->context);
mycpu()->intena = intena;
}可以发现,sched 函数只是做了一些合理性检查,如果发现异常就 panic。我们直接走到位于底部的 swtch 函数。这个函数是线程调度的核心。
swtch 函数有两个参数,一个是将被保存的PC 和callee 寄存器 的地址,另一个是将恢复的 PC 和callee 寄存器 的地址。
swtch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret你会发现没有 PC 啊,你是不是写错了。停,真正好玩的地方出现了。让我们想想在 CPU 的流水线中 PC 是做什么的,对他就是一个指标,PC 指哪里的地址我们的 CPU 就做什么操作,寄存器真是"呆呆的",因为我只要改变了 PC 的值 CPU 不管和之前的相不相关,它都"呆呆的"去执行,而我们是不是调用了 swtch 函数,那么就是说 PC -> swtch 指向地址,那么 RA <- PC + 4 ra 寄存器 是保存了 swtch 函数的返回地址即下一句 mycpu()->intena = intena; 这是我保存的寄存器,那恢复的寄存器中 RA 是不是就是另一个 PC ,之后我返回 swtch 函数 PC 的值更新为恢复的 RA 0(a1)的值。我写到这个不得不佩服发现这个的天才啊。
<p>问题:为什么 RISC-V 中有32个寄存器,但是 swtch 函数中只保存并恢复了14个(callee)寄存器? 因为 <code>swtch</code> 是按照一个普通函数来调用的,对于有些寄存器,<code>swtch</code> 函数的调用者(<code>sched</code>)默认 <code>swtch</code> 函数会做修改,所以调用者已经在自己的栈上保存了这些寄存器,当函数返回时,这些寄存器会自动恢复。所以 <code>swtch</code> 函数里只需要保存 Callee Saved Register 就行。</p>
最后是sp(Stack Pointer)寄存器。它实际是当前进程的内核栈地址,它由虚拟内存系统映射在了一个高地址。
<p>问题:为什么我们恢复的是来自 CPU 调度器线程的 context 对象 <code>&mycpu()->context</code> 中的内容? 因为在之前 <code>ls</code> 程序的内核线程对应的内核寄存器也已经保存在对应的 context 对象中,即 CPU 0 中的 context 。</p>
一旦 swtch 返回,那么现在PC指向了 scheduler 函数,因为这是我们恢复了调度器线程的 context 对象中的内容。
调度器线程 scheduler 函数,Per-CPU 进程调度程序对于每个 CPU 在设置好自己之后都要调用 scheduler()。就是将一个 RUNNABLE 线程转换成一个 RUNNING 线程的过程。
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// Avoid deadlock by ensuring that devices can interrupt.
intr_on();
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&p->lock);
}
}
}其实可以猜猜我现在的 PC 指那里,对,指向 c->proc = 0;,进行设置现在并没有在这个 CPU0 核上运行的进程。之前在 yield 函数中获取了进程的锁,因为 yield 不想在进程完全进入到 Sleep 状态之前,有任何其他的 CPU 核的调度器线程看到这个进程并运行它。而现在我们做完了,所以现在可以释放锁了(蛮远的)。ok,现在 CPU0 为空了,它可以去找其他的为 RUNNABLE 的进程了,回到一开始还记得我们有两个 CPU 吗?我们一直没用到 CPU1 ,现在你应该知道它要做什么了,它一直在 scheduler 中找适合的进程,你看,我们之前把 shell 进程 RUNNABLE 了,CPU1 可以去执行它了。而我的 CPU0 可能去执行 ls 了。
<p>问题:如果不是因为定时器中断发生的切换,我们是不是可以期望 ra 寄存器指向其他位置,例如 sleep 函数? Robert 教授:是的,我们之前看到了代码执行到这里会包含一些系统调用相关的函数。你基本上回答了自己的问题,如果我们因为定时器中断之外的原因而停止了执行当前的进程,switch 会返回到一些系统调用的代码中,而不是我们这里看到 sched 函数。我记得 sleep 最后也调用了 sched 函数,虽然 bracktrace 可能看起来会不一样,但是还是会包含 sched。所以我这里只介绍了一种进程间切换的方法,也就是因为定时器中断而发生切换。但是还有其他的可能会触发进程切换,例如等待 I/O 或者等待另一个进程向 pipe 写数据。</p>
线程除了寄存器以外的还有很多其他状态,它还有变量,堆中的数据等等,但是所有的这些数据都在内存中,并且会保持不变。我们没有改变线程的任何栈或者堆数据。所以线程切换的过程中,处理器中的寄存器是唯一的不稳定状态,且需要保存并恢复。而所有其他在内存中的数据会保存在内存中不被改变,所以不用特意保存并恢复。我们只是保存并恢复了处理器中的寄存器,因为我们想在新的线程中也使用相同的一组寄存器。我认为不改变其他状态是因为 CPU 之间也是内核线程之间是共享内存的。